
Figure 1: Quartet card
catholic youth work
Until now the Gazette has not paid much attention to the theory of income distribution. However, this theory is indispensable in the analysis of the welfare state. Therefore the present column discusses the main principles. The difference between gross and nett incomes is explained. Various pictures of the income inequality are shown, such as the frequency distribution and the Lorenz diagram. Several common measures of income inequality are described, among others the parameter of Pareto and the Gini coefficient.
More than five years ago the then chairman Spekman of the PvdA made the surprising remark: "The levelling of incomes is a joy!" His remark caused so much hilarity, that "levelling party" was almost chosen as the expression of the year 2012. The reality is evidently more complex, and the present column wants to give some insights into the optimal and fair distribution of incomes1. This is an elaboration of a long series of articles, which study various income aspects. Sam de Wolff, the name-giver of the Gazette, shows that the disutility of work must be compensated by a reward. A column from 2013 describes how the Belgian politician Hendrik de Man summarizes the various factors, which contribute to the displeasure of work. Moreover, he shows that the reward partially consists of non-monetary factors.
In the same year a column appeared, which discusses the compensating wage differences. Workers choose their job not purely on the basis of the wage, but they also take into account the secondary job conditions. During the sixties the Dutch economist Jan Tinbergen presented this phenomenon as a theory of tension. According as the job demands sn deviate more from the properties tn of the worker, his disutility of work will increase. When the worker is under-qualified (say, tn < sn), then he will probably be compensated with a relatively high wage2. A year ago all these models have been summarized again in a separate column. Here the following formula is takes as the starting point:3
(1) u(e, w) = v(w) − c(e)
In the formula 1, u is the utility (job satisfaction) of the worker. It is composed of two parts, namely the pleasure v(w) due to the wage w, and the displeasure (costs) c due to the effort e. An important goal of such models is evidently to justify the really paid money wages w. Whenever possible, Tinbergen wants to establish work classifications, and calculate from them the corresponding wage w. The Dutch economist Bernard van Praag has determined empirically, how the various factors at work contribute to the satisfaction u of the job. It turns out that the job contents is more important for u than the wage height4. Van Praag succeeds in measuring the preferences of the average or representative worker, and therefore describes the relation with the macro level of the economy.
Already in 2013 a column discussed the study by Jacob van der Wijk, a friend of De Wolff, who indeed analyzes the income distribution at the macro level. Van der Wijk elaborates on the spread of the incomes, as well as the effects of inequality on the wellbeing of individuals. Since this is an analysis at the macro level, Van der Wijk can not take into account various factors, which compensate the inequality in incomes. Here one identifies also the evident logical error in the cited remark of Spekman. This makes his statement unfair. For, the differences in money wages, are mainly caused by free choices. The individual chooses his own education, working hours, industrial sector, or composition of the household. Those who want to judge the justice or fairness of wage differences, must take this into account. The present column wants to elaborate on such considerations. Therefore the formula 1 is rewritten as5
(2) u(w, a) = v(w) + ω(a)
In the formula 2, a represents the labour conditions, with the exception of the wage w, and ω(a) is the total utility, which these labour conditions yield. So the formula 2 separates the rewards in money from the immaterial rewards. Many economists believe, that the fairness of society must be tested against the levelling of u(w, a) (so not of w)6. However, here it must be remembered, that the state has many goals, which are at least as important as fairness or justice. The state must realze all of these goals in the best possible manner, with a fit weighing factor for each goal, and therefore tries to realize the optimal income distribution7. In spite of many attempts to measure ω(a), this term remains quite speculative. Therefore the economic science has yet mainly studied the income distribution, so the incomes wk of all K citizens or households.
The introduction of this column actually only considers incomes from labour. However, it is common that a part of the individual income is not related to labour. It consists of for instance interest, or (house) rent, thanks to the property of respectively capital, land, or real estate. The profit of the entrepreneur also is an income, due to labour or not8. All of these incomes are rewards for production factors. The rewards express the scarcity of these factors on their respective markets. The incomes on the factor markets are not yet taxed. These are called the primary incomes, in short YP. However, these incomes are not freely available for the receivers. For, the state must also be paid, and he obtains his financial means by imposing taxes on the private incomes. Moreover, the individuals are obliged to pay premiums for the various employee- and employer-insurances.

So the state reduces YP by means of his direct income taxes. On the other hand, the state sometimes also increases the incomes, by means of transfers such as subsidies and benefits. The direct taxes and the transfers determine together, what the really available income of the individual is. The available income is called the secondary income, in short YS. Since mainly the poor individuals qualify for benefits, the distribution of YS is somewhat more equal than the distribution of YP. Although YS is completely available to the individual, this does not yet finalize the state intervention. Namely the state also imposes indirect taxes, on consumption. Consider the VAT (tax on added value), excise duties (taxes on alcohol etcetera) and import levying. Some believe, that the indirect taxes lead to a greater inequality. Namely, it does not effect the savings9.
So strictly speaking the income must be corrected for the effects of indirect taxes, notably when one is interested in inequality (differences in really available incomes). Furthermore, the state uses a part of its financial means for supplying public goods and services, which are consumed in kind, such as education, health care and culture. They are immaterial benefits of the type ω(a) for the users. Collective goods such as defence and justice can also be included in the individual benefits. According to the formula 2 such benefits must be added to the individual income. When the secondary income is corrected for the effects of indirect taxes and of the individually consumed public facilities, then the so-called tertiary income is found, in short YT. State interventions guide society, and therefore also change YP10.
Until now the focus is on the individual income. However, individuals often live in households, which consist of a number of persons f. These f individuals together will share the income of the household. Here they profit from advantages of scale, because many domestic appliances can be mutually shared. Consider the television set, heating, books, clocks, to a lesser extent also the washing machine and the car, etcetera. A child consumes less than an adult. Thus a false impression could be created, when the individual income is calculated simply by dividing the aggregate income of the household by f. Nowadays the European Union and the OECD both use an equivalence scale for adults, which within the household weighs each extra adult by 0.5, and each child by 0.3. In other words, in a household with n adults and m children f is corrected by means of f' = 1 + (n−1) × 0.5 + m×0.3 11.
Dependent on the theme, analyses study the incomes per individual or per (member of the) household. Such incomes are called personal. It has just been remarked, that an individual or household can own various production factors. The interest of economists is strongly focused on the incomes of these factors. The income of a factor is called functional, because each factor has its own function within the production process, In the present column the focus is on the personal distribution, and the functional distribution is merely of an incidental importance12.
The analysis of the distribution of incomes gives insight in the fairness of society. Suppose that the society consists of N individuals (or households). Let yn be the personal income of the individual n (with n=1, ..., N). Reorder the individuals into a row with increasing yn. Then one finds the curve, which is shown in the figure 3a. Each n on the horizontal axis is coupled to a "bar", which is as high as his income yn. This is called the procession of Pen13. For comparison, the figure 3a also shows the average income yg per individual. The procession is naturally discrete in n, but it is mathematically convenient to approach the distribution y1 ≤ y2 ≤ ... ≤ yN by a continuous function y(n). Moreover, the size N of the population is irrelevant, so that n can be normalized on N without loss of information. So suppose, that Ω=n/N can assume all values between 0 and 1. Then y = P(Ω) holds, where P is the Pen curve in the figure 3a.
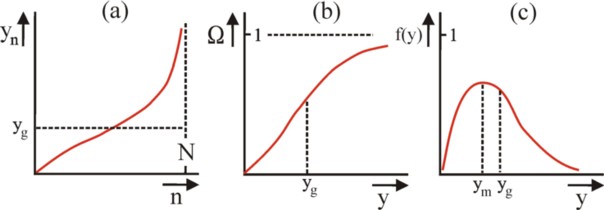
Now the frequency- or probability-distribution of the incomes can simply be derived from P. For, Ω = P-1(y) holds, where P-1 is the inverse function of P. It is shown in the figure 3b. Actually the axes in the figure 3a have simply been interchanged (and n is normalized into Ω). Since Ω increases vertically from 0 to 1, the function P-1(y) can be interpreted as the cumulative distribution function of the incomes y. Therefore f(y) = ∂P-1/∂y is the frequency distribution (density function) of y. See the figure 3c. It is skewed. In other words, the most often occurring income ym (the modus) is less than the average income yg. This will not surprise the loyal reader, For, a previous column explains, that according to the sociological thinker J. van der Wijk y = μ + eu/κ holds, where μ and κ are constants, and u is a Gaussian distribution around zero. This causes a long "tail" of high incomes.
A more interesting aspect of the row of Pen (y = P(Ω)) is, that it allows to simply construct the so-called Lorenz diagram. For this purpose, define the cumulated income Y(n) as the summation of the incomes of all individuals between 0 and n in the figure 3a. This is to say, Y(n) = ∫0n y(ν) dν= ∫0Ω×N y(ν) dν = N × ∫0Ω y(ξ) dξ = N × ∫0Ω P(ξ) dξ. For n=N this is dit a summation over all individuals N, so that Y(N) = N×yg equals the total income of society. Define the normalized cumulated income as Ψ(Ω) = Y(n) / Y(N) = Y(N×Ω) / Y(N), so that Ψ varies between 0 and 1, just like Ω itself. Then Ψ(Ω) is the so-called Lorenz curve. She is shown in red in the figure 4, for the row of Pen in the figure 3a.
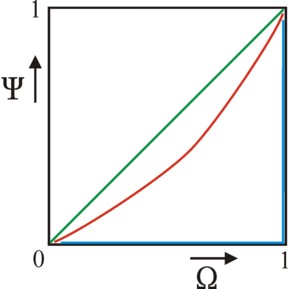
The Lorenz diagram presents the inequality in a peculiar way. For complete equality one has yg = P(Ω), so that Ψ(Ω) = Ω must hold. Then apparently the Lorenz curve is the green diagonal in the figure 4. In maximal inequality the individual N owns the total income Y(N). This can mathematically be represented as a delta function, namely P(Ω) = Y(N) × δ(Ω−1). Now the Lorenz kromme curve follows the blue trajectory (Ω, Ψ) = (0,0) - (1,0) - (1,1) in the figure 4. All other Lorenz curves lie between the green and blue extreme situations. Finally, note that the Lorenz diagram, and incidentally als the figures 3a-c, can be constructed for the primary and secondary incomes, as well as for individuals and households.
The previous paragraph has discussed various ways to depict the income distribution. However, such pictures merely present a qualitative comparison between the various distributions. Quantitative comparisons are more clarifying, and therefore, for a long time science has tried to find convenient indicators (measures) of inequality. Besides, there is obviously the hope, that the analysis of distributions will lead to a sound economic theory. Unfortunately, until now this hope is idle, because an all encompassing model is still missing. One must be contented with semi-empirical models, which moreover only describe a part of the distribution14.
An evident approach is to strongly compress the frequency distribution. For, it is impossible to compare all personal incomes yn (with n=1, ..., N) with each other. Therefore an empirical analysis will always restrict itself to the distribution over groups. This inevitably destroys information. This is particularly clear in the computation of the average income, which makes the distribution invisible. Commonly, the separate incomes are aggregated (collected) in quantiles. This is to say, first the personal incomes are ordered according to increasing incomes (row of Pen). Subsequently this row is split into Q groups (with N/Q members each). The income φ(q) per group q is determined by φ(q) = Σn=j+1j+N/Q yn, where j = (q−1) × N/Q. Finally, each quantile is also normalized, with Φ(q) = φ(q) / Y(N). The cases Q=4, 5, 10 and 100 are called respectively a quartile, quintile, decile and percentile.
Therefore the first quantile (q=1) unites the N/Q lowest incomes, and the last (q=Q) quantile unites the N/Q highest. Those who want to study poverty, will analyze mainly q=1. When the quartiles are preferred. then q=2 and 3 represent the lower and higher middle classes. The continuous row of Pen P(Ω) has changed into a discrete bar graph Φ(q).
The well-known economist V. Pareto believes, that the distribution is characterized by a single parameter α. For this reason he considers the variable R(y) = ∫y∞ f(η) dη. By definition this cumulative function equals R(y) = 1 − P-1(y). Apparently this curve is the figure 3b on its head. Pareto supposes, that the tail of R(y) (so the higher incomes) is described by R(y) = c / (y − d)α. Here c is a scaling factor, and d is a lower threshold of y. Obviously the problem of this model is, that due to the threshold the lowest incomes are not taken into account. The model is mainly useful for the analysis of the higher incomes. Besides, the measure α does not give a theoretical explanation15.
The coefficient of Gini (G) is a popular measure for the inequality of the distribution. G is defined by means of the Lorenz diagram. Namely, G is simply twice the surface between the diagonal and the Lorenz curve in the figure 4. Thanks to the multiplication by 2, G has values between 0 (for an egalitarian distribution yn=yg) and 1 (for total inequality yN = N×yg). Unfortunately, there is no clear theoretical interpretation connected to G. Your columnist has also found two formulas for computing G16. The first one is
(3) G = (2 × N² × yg)-1 × Σn=1N Σk=1N |yn − yk|
The second one is, with y1 ≤ y2 ≤ ... ≤ yN,
(4) G = 1 + 1/N − 2 × (N² × yg)-1 × Σn=1N (N − n + 1) × yn
The economist A.B. Atkinson has invented the A measure of inequality17. A is calculated by forming groups of individuals or households, similar to quantiles. However, now the various groups are not all equally large. This is to say, the group q has nq member, with evidently Σq=1Q nq = N. The definition is
(5) A = 1 − ( Σq=1Q nq × (Y(q) / (nq×yg))1-ε )1/(1-ε)
Note that one always has A=0 for a completely egalitarian distribution. In the formula 5, ε is the parameter of inequality avoidance. The goal of this parameter is to base the measure of inequality on the social morals. For ε=0 the society believes that inequality is irrelevant. Therefore, in this situation A=0 holds, irrespective of the distribution. According as ε becomes larger, then A will also increase for a given distribution. It seems that A can indeed be derived from a social welfare function18. Therefore the A measure has a theoretical meaning. Atkinson uses in his model individual utility functions of the form u(yn) = yn1-ε / (1 − ε) 19. This is a fascinating matter, which will undoubtedly yet be elaborated in the Gazette.